
具身Scaling Law押对了!独角兽新品1小时学会新任务,重复1800次成功率99%
具身Scaling Law押对了!独角兽新品1小时学会新任务,重复1800次成功率99%具身智能独角兽Generalist,刚刚推出了最新的研究成果——新模型Gen-1。在包装手机和折叠纸箱这些精细活儿上,它把机器人的成功率从64%硬生生拉到了99%,几乎告别了手残职业病。
来自主题: AI资讯
9456 点击 2026-04-06 09:40
 搜索
搜索
具身智能独角兽Generalist,刚刚推出了最新的研究成果——新模型Gen-1。在包装手机和折叠纸箱这些精细活儿上,它把机器人的成功率从64%硬生生拉到了99%,几乎告别了手残职业病。

具身数据层的全球竞赛正在迅速升温。NVIDIA Research在2026年发布EgoScale数据与训练框架,在Ego-centric人类操作视频上训练VLA模型,用 20,854小时带动作标注的第一人称人类视频,观察到数据规模和验证损失之间接近对数线性的scaling law。1X收集人类第一视角及家庭行为数据,通过 Sunday项目采集百万小时级家庭场景视频。

三周前那个疯狂传言,如今被Mythos彻底印证?Anthropic或已完成史上最大规模训练,新模型性能或将达到预期的2倍,翻倍碾压Scaling Law!一场颠覆性变革正在降临,算力、能源成为终极筹码,创业公司恐遭毁灭性降维打击!
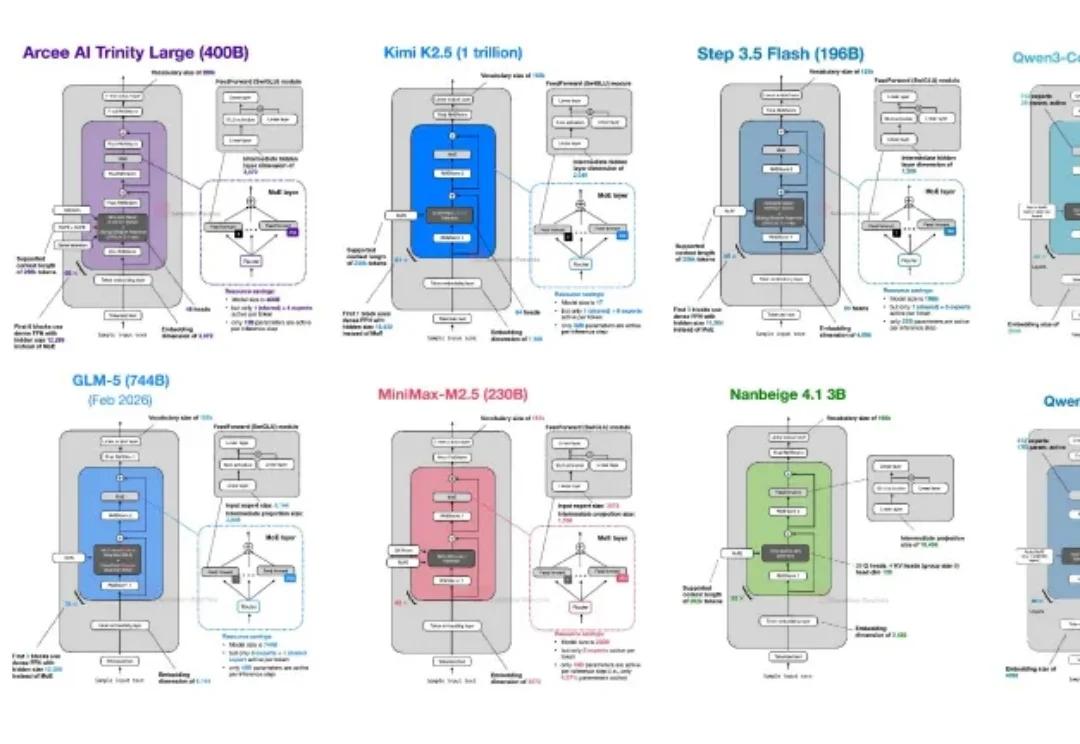
这两年,大模型大厂之间堪比军备竞赛。不论开源还是闭源阵营,为了在指标上领先对手,都在疯狂地卷 Scaling Law,卷算力,卷参数量,已经达到了近乎离谱的程度。
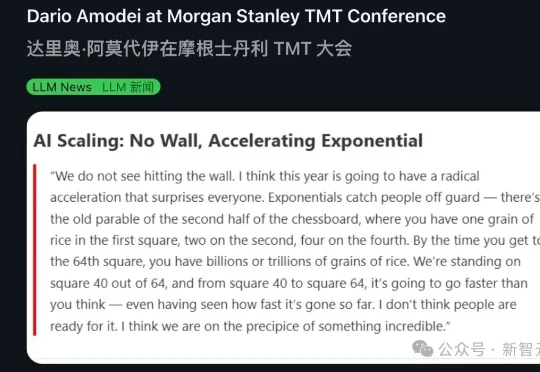
Anthropic CEO Dario Amodei在摩根士丹利会议上扔出一颗深水炸弹:Scaling Law根本没撞墙,2026年将迎来激进加速。他用棋盘稻米寓言做了个精准比喻——我们正站在第40格,前39格的所有震撼加在一起,不过是后24格的零头。这场指数级狂飙,没人准备好。

思考token在精不在多。Yuan 3.0 Flash用RAPO+RIRM双杀过度思考,推理token砍75%,网友们惊呼:这就是下一代AI模型的发展方向!
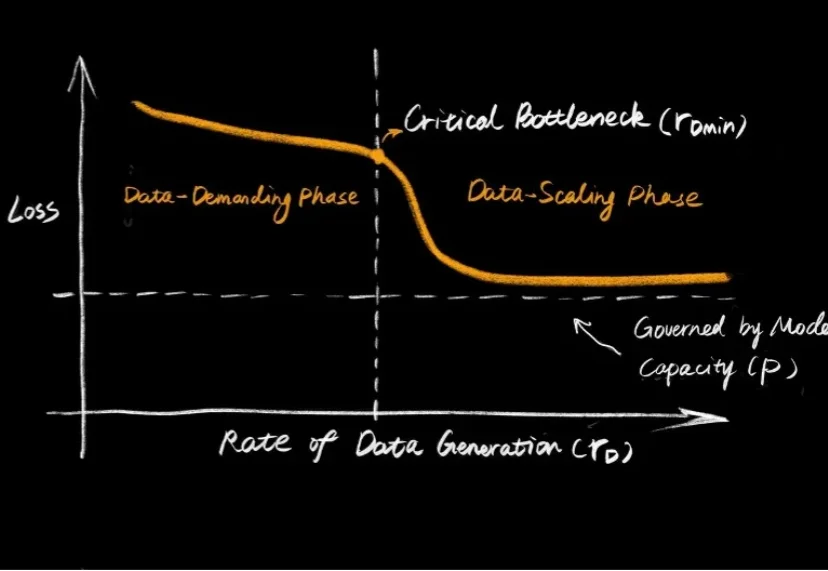
大语言模型的爆发,让大家见证了 Scaling Law 的威力:只要数据够多、算力够猛,智能似乎就会自动涌现。但在机器人领域,这个公式似乎失效了。

2026 年危机逼近,OpenAI 虽创下 400 亿美元融资纪录,但内部预测 2028 年亏损将扩大至 450 亿美元。不同于有传统业务「输血」的科技巨头,独立 AI 公司受困于 Scaling Laws 带来的指数级成本爆炸。奥特曼的万亿豪赌或难以为继,OpenAI 恐面临被吞并结局,AI 泡沫时代即将硬着陆。
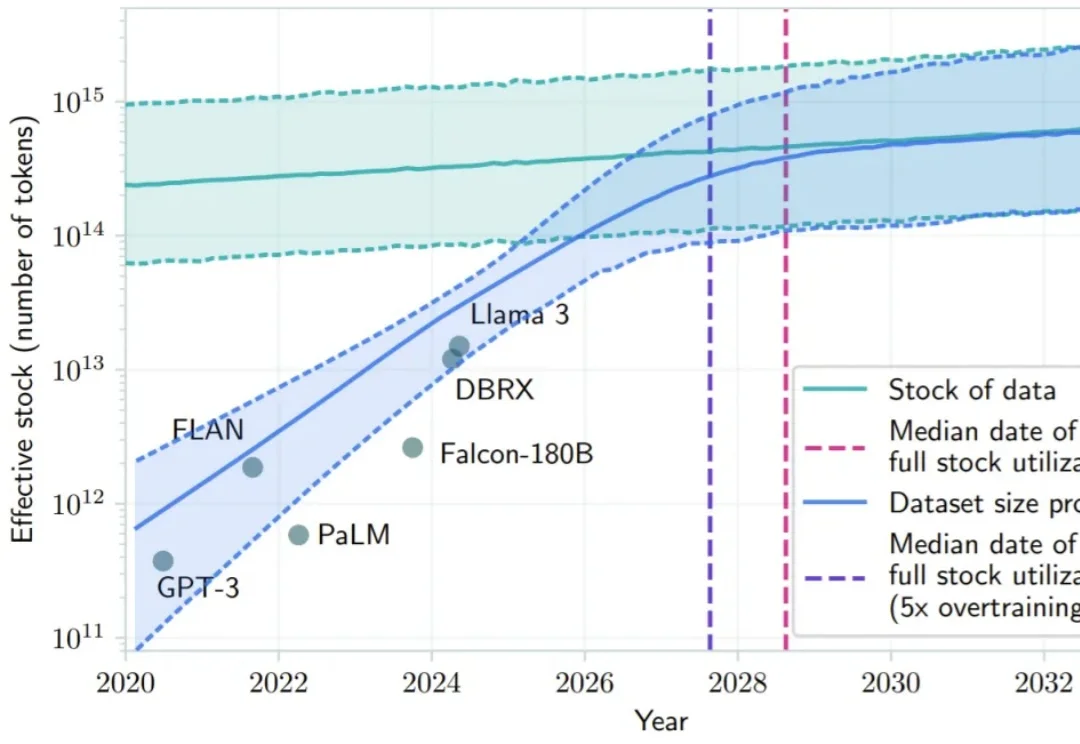
2024 年底,硅谷和北京的茶水间里都在讨论同一个令人不安的话题:Scaling Law 似乎正在撞墙。

2026年,Scaling Law是否还能继续玩下去?对于这个问题,一篇来自DeepMind华人研究员的万字长文在社交网络火了:Scaling Law没死!算力依然就是正义,AGI才刚刚上路。